在现实生活中很多机器学习问题有上千维,甚至上万维特征,这不仅影响了训练速度,通常还很难找到比较好的解。这样的问题成为维数灾难(curse of dimensionality)
幸运的是,理论上降低维度是可行的。比如 MNIST 数据集大部分的像素总是白的,因此可以去掉这些特征;相邻的像素之间是高度相关的,如果变为一个像素,相差也并不大。
在现实生活中很多机器学习问题有上千维,甚至上万维特征,这不仅影响了训练速度,通常还很难找到比较好的解。这样的问题成为维数灾难(curse of dimensionality)
幸运的是,理论上降低维度是可行的。比如 MNIST 数据集大部分的像素总是白的,因此可以去掉这些特征;相邻的像素之间是高度相关的,如果变为一个像素,相差也并不大。
1 | 点我达大数据团队初创于2015年,随着公司业务发展,大数据对于公司的业务发展发挥了越来越大的作用,目前服务的用户/团队包含BI、产品运营、运力中心以及技术内部应用的数据服务等 |
目前大数据主要的结构如下:
 从最下面一层往上依次为:
从最下面一层往上依次为:
一、接入层
1、DataX
a) dataX 是一个 ETL 工具,阿里出品
b) 采用 Framework + plugin 架构构建,幸运的是自带了常用的插件,比如 MysqlReader、HdfsWriter 等
c) Standalone,无中心,每个实例之间无关联
d) 性能强劲、相对于 sqoop,配置更简单
e) 稳定高效,我们引入 DataX 以来,从来没有在数据传输上出过问题
在之前学习机器学习技术中,很少关注特征工程 (Feature Engineering),而且机器学习的书中基本上是已经处理好的数据或者作者自己构造的虚拟的数据。所以在机器学习的实践中,可能会选择使用这些算法,但是常常不知道怎么提取特征来建模。因此,结合网上的资料和项目中的经验试着来总结一下。
特征是对于分析和解决问题有用、有意义的属性。例如:
在表格数据中,表格中的一行是一个观测,但是表格的一列可能才是特征;
在机器视觉中,一幅图像是一个观测,但是图中的一条线可能才是特征;
在自然语言处理中,一个文本是一个观测,但是其中的段落或者词频可能才是一种特征;
在语音识别中,一段语音是一个观测,但是一个词或者音素才是一种特征。
1、R+pmml+spark+airflow 调度
其他团队用 R 语言训练模型并转为 pmml 文件,然后我们使用 spark 将这个 pmml 文件封装为 jar,使用 airflow 提交到 yarn。 val is: InputStream = fs.open(path) val pmml: PMML = PMMLUtil.unmarshal(is) modelEvaluator = ModelEvaluatorFactory.newInstance.newModelEvaluator(pmml)
FM 模型是最近几年提出的模型,凭借其在数据量比较大并且特征稀疏的情况下,忍让能够得到优秀的性能和效果,屡次在各大公司举办的 CTR 预估比赛中获得不错的战绩。
在计算广告领域,点击率 CTR(click-through rate)和转化率 CVR(conversion rate)是衡量广告流量的两个关键指标。准确的估计 CTR、CVR 对于提高流量的价值,增加广告收入有重要的指导作用。预估 CTR、CVR,业界常用的方法由人工特征工程 + LR(Logistic Regression)、GBDT(Gradient Boosting Decision Tree)+LR、FM(Factorization Machine)和 FFM(Field-aware Factorization Machine)模型。在这些模型中,FM 和 FFM 近年来表现突出,分别在 Criteo 和 Avazu 举办的 CTR 预测竞赛中夺得冠军。
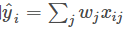 。这里的预测 y 可以有不同的解释,比如我们可以用它来作为回归目标的输出,或者进行 sigmoid 变换得到概率,或者作为排序的指标等。而一个线性模型根据 y 的解释不同(以及设计对应的目标函数)用到回归,分类或排序等场景。 参数指我们需要学习的东西,在线性模型中,参数指我们的线性系数 w。
。这里的预测 y 可以有不同的解释,比如我们可以用它来作为回归目标的输出,或者进行 sigmoid 变换得到概率,或者作为排序的指标等。而一个线性模型根据 y 的解释不同(以及设计对应的目标函数)用到回归,分类或排序等场景。 参数指我们需要学习的东西,在线性模型中,参数指我们的线性系数 w。
















